
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 스위프트
- Git
- property
- Foundation
- tuist
- 디자인패턴
- Xcode
- optional
- UIKit
- String
- interpace
- delegate
- Swift
- Terminal
- enum
- extension
- 이니셜라이저
- initializer
- init
- initalizer
- Method
- Protocol
- type
- instance
- Class
- IOS
- url
- Unicode
- 코딩테스트
- struct
- Today
- Total
아리의 iOS 탐구생활
ASCII, Unicode, UTF-8 문자표(CharacterSet)와 인코딩 본문
문자표와 문자표를 인코딩 한다는 개념 두가지를 기억하자.
유니코드는 국제표준 문자표이고 UTF-8은 인코딩 방식이다.
문자표(Character Set)란?
ASCII, Unicode, UTF-8은 간단하게 요약하면 문자들을 숫자와 1대 1로 매칭시키는 것을 문자표라고 이야기할 수 있겠다. 우리가 단어장을 외우듯이 컴퓨터가 인간의 문자를 알아볼 수 있도록 인간의 문자를 컴퓨터가 읽을 수 있는 숫자의 형태로 표를 만들어서 컴퓨터에게 입력해주는 것이다. 대표적인 것은 아스키 코드표(ASCII)가 있겠다.
그러나 아스키는 영어권에서만 쓸 수 있어서 다른나라 언어의 문자표도 생기기 시작하였다. 그러나 너무 많은 문자표가 생겨버려서 컴퓨터가 혼란에 빠지자 '너무 많은 표준이 있으니 혼란스럽다. 하나로 다 통합하자!', '하나의 코드표를 만들어서 모든 세계의 문자를 다 거기에서 표현할 수 있게끔 만들자' 라고 해서 나온게 유니코드(Unicode)이다.
그런데 이러한 유니코드도 문제점이 발생하게 되는데, 유니코드가 영어를 표현할 때에는 한 바이트, 한글을 표현할 땐 두바이트, 그리고 다른나라 어떤 특수 문자를 표현할 때에는 세 바이트로 표현하는 이런 가변적인 표현이 문제가 되었다.
그래서 컴퓨터가 혼란스럽지 않도록 유니코드 앞에 어떤 표시를 하게된다. 그래서 이 표시가 있을 때는 한 바이트 만 읽고, 또 다른 표시가 있으면 '한 바이트가 아니라 2바이트로 읽어' 그리고 또 다른 표시가 있으면 '이건 3바이트로 읽어서 표현해줘' 라는 약속을 또 하게되고 그 약속대로 저장하는데 그게 인코딩이라는 것이다. 쉽게 얘기해서 파일로 저장할 때 단순히 유니코드로만 저장하면 혼란을 주게 되니 유니코드 앞에 어떤 표를 하나 더 달아서 저장하게 되었다. 그게 인코딩이다 라고 생각하면 될 것 같다.
그 방법들이 하나가 아니고 UTF-8 도 있고, UTF-16, UTF-32 등 여러종류가 있다 라는 것을 알고 있으면 될 것 같다.
가끔 어떤 사이트를 접속하거나 외국의 프로그램을 다운받아서 사용하다보면 한글이 깨져서

위와 같은 이상한 문자가 나타나는 경우가 종종 있는데 이렇게 문자가 깨지는 이유는
바로 문자를 표기할 때 사용하는 문자표가 다르기 때문이다.
UTF란?
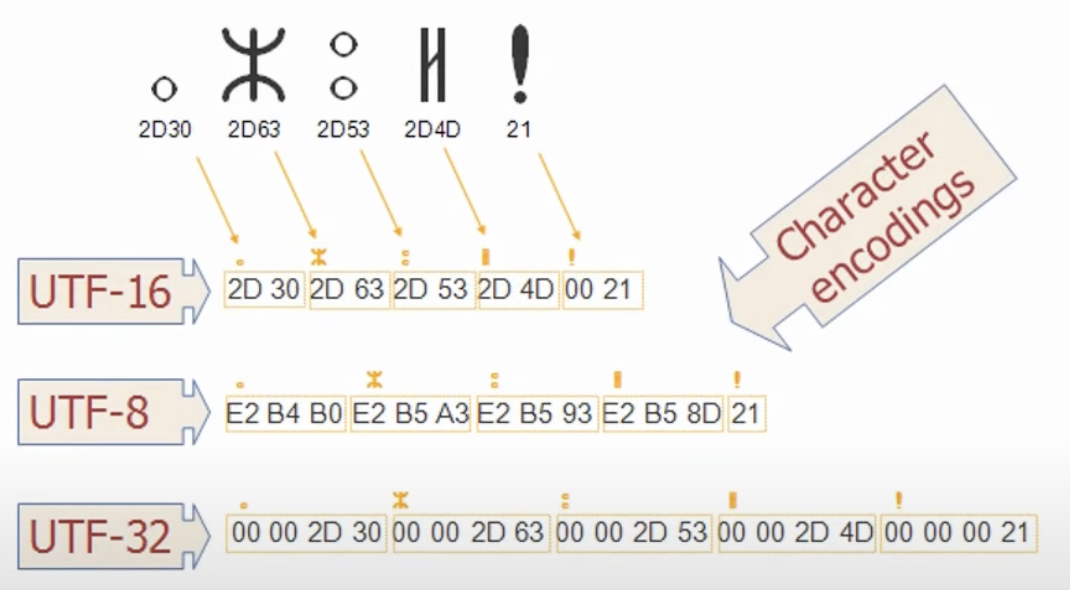
UTF 뒤에 오는 16, 8, 32는 글자를 담는 크기라고 이해할 수 있겠다. 사진을 보면 특수문자를 각각 UTF-16, 8, 32로 표기하고 있는데, 이 때 같은 문자이지만 UTF에 따라 저장하는 크기가 다른 것을 볼 수 있다.
이렇게 인코딩 방식을 여러개로 만들어 둔 이유는 문자마다 인코딩 방식에 따라 효율성이 다르기 때문이다.
컴퓨터의 물리적인 공간은 한정적이고 데이터를 보낼 때 컴퓨터가 연산할 수 있는 양, 네트워크로 전송할 수 있는 양은 최대한 줄이는 것이 좋다. 예로 UTF-16과 UTF-8의 크기 차이를 들 수 있겠다. UTF-8은 8이 붙은 것 처럼 문자를 표현하는데 8bit(1byte)가 소요된다. UTF-16은 16bit(2byte)를 차지한다.
오로지 한글만 사용한다고 할 경우에는 UTF-16이 더 유리하다. UTF-8의 경우 글자당 24비트를 차지하니 UTF-16에 비해 1.5배나 큰 메모리를 사용할 것이다. UTF-32는 지금으로서 가장 마지막에 추가된 문자일 확률이 높기 때문에 아직 자주 사용되지는 않는다고 한다.
그러나 현재는 UTF-16이 유리한 경우에도 메모리의 불이익이 있더라도 호환성 문제 때문에 UTF-8을 선택하는 경우도 많다고 한다.
Reference
문자열 인코딩 완벽 정복하기(for 개발자)
문자열 인코딩! 어느날 친구가 물어봅니다. "OO아~ 문자열 인코딩이 뭐야?" 갑자기 머릿속이 하얗게 변합니다. 문자열 인코딩... 분명 들어본적은 있는데 말이죠. 기억을 마구 더듬어봅니다. 예전
redisle.tistory.com
'CS' 카테고리의 다른 글
| [iOS] Design Pattern과 Architectures (0) | 2021.10.20 |
|---|---|
| 메모리 구조에 대해서 알아보자. (0) | 2021.08.12 |

